




Report: The Risk of Generative AI and Large Language Models




Generative AI has reshaped the digital content landscape, with Large Language Models (LLMs) like GPT pushing the boundaries of what machines can create. However, as this technology rapidly enters the market, are we giving enough attention to its security aspects and generative AI risk?
In the following research, we delve deep into the risks associated with Generative AI models and specifically LLMs, shedding light on the potential threats organizations face. AI introduces both novel and familiar risks. On one hand, it brings new threat vectors that demand attention and awareness. On the other hand, it exposes existing security risks that are often overlooked when utilizing AI systems. Our research emphasizes the need to address these risks head-on and foster a security-first approach to AI adoption.
We categorize these risks into Trust Boundaries, Data Management, Inherent Model, and General Security Best Practices, providing a comprehensive understanding of each category.
These risks can lead to bypassing access controls, unauthorized access to resources, system vulnerabilities, ethical concerns, potential compromise of sensitive information or intellectual property, and more. By exploring their manifestations and providing mitigation strategies, we equip organizations with the knowledge to navigate these security challenges effectively.
Additionally, we uncover a concerning finding: the open-source ecosystem surrounding LLMs lacks the maturity and security posture needed to safeguard these powerful models. As their popularity surges, they become prime targets for attackers. This highlights the urgency to enhance security standards and practices throughout the development and maintenance of LLMs.
Our assessment of the security state of open-source projects relies on the OpenSSF Scorecard framework, developed by the Open Source Security Foundation (OSSF). This framework, an automated SAST (Static Application Security Testing) tool, evaluates the security of projects by assigning scores to various security heuristics or checks. With scores ranging from 0 to 10, it provides valuable insights into areas that require improvement and helps enhance the overall security of projects. By utilizing the Scorecard, developers can assess the risks associated with dependencies, make informed decisions regarding these risks, and even collaborate with maintainers to address security gaps. Moreover, when comparing similar projects, the Scorecard assists in prioritizing security considerations and selecting the most secure options.
In our analysis, we focused on the security posture of the 50 most popular LLM/GPT-based open-source projects. By comparing their security posture to that of other widely-used open-source projects, including critical ones designated by the OpenSSF Securing Critical Projects Work Group, we highlight the potential risks associated with relying on emerging GPT projects. This examination provides valuable insights into the security posture of these projects and underscores the importance of considering security factors when choosing software solutions.
The key findings highlight concerns, revealing very new and popular projects with low scores:
- Extremely popular, with an average of 15,909 stars
- Extremely immature, with an average age of 3.77months
- Very poor security posture with an average score of 4.60 out of 10 is low by any standard. For example, the most popular GPT-based project on GitHub, Auto-GPT, has over 140,000 stars, is less than three months old, and has a Scorecard score of 3.7.
As can be seen in the below visualization comparing three of the most popular LLM-based projects (Auto-GPT, Langchain, and GPT-Engineer), with three other non-GPT related projects from the OpenSSF critical open-source projects list (TensorFlow, Node.js, and Flutter), the LLM projects achieved in several weeks the same popularity that the more mature projects took years to achieve. While the security posture of these projects is far from ideal.
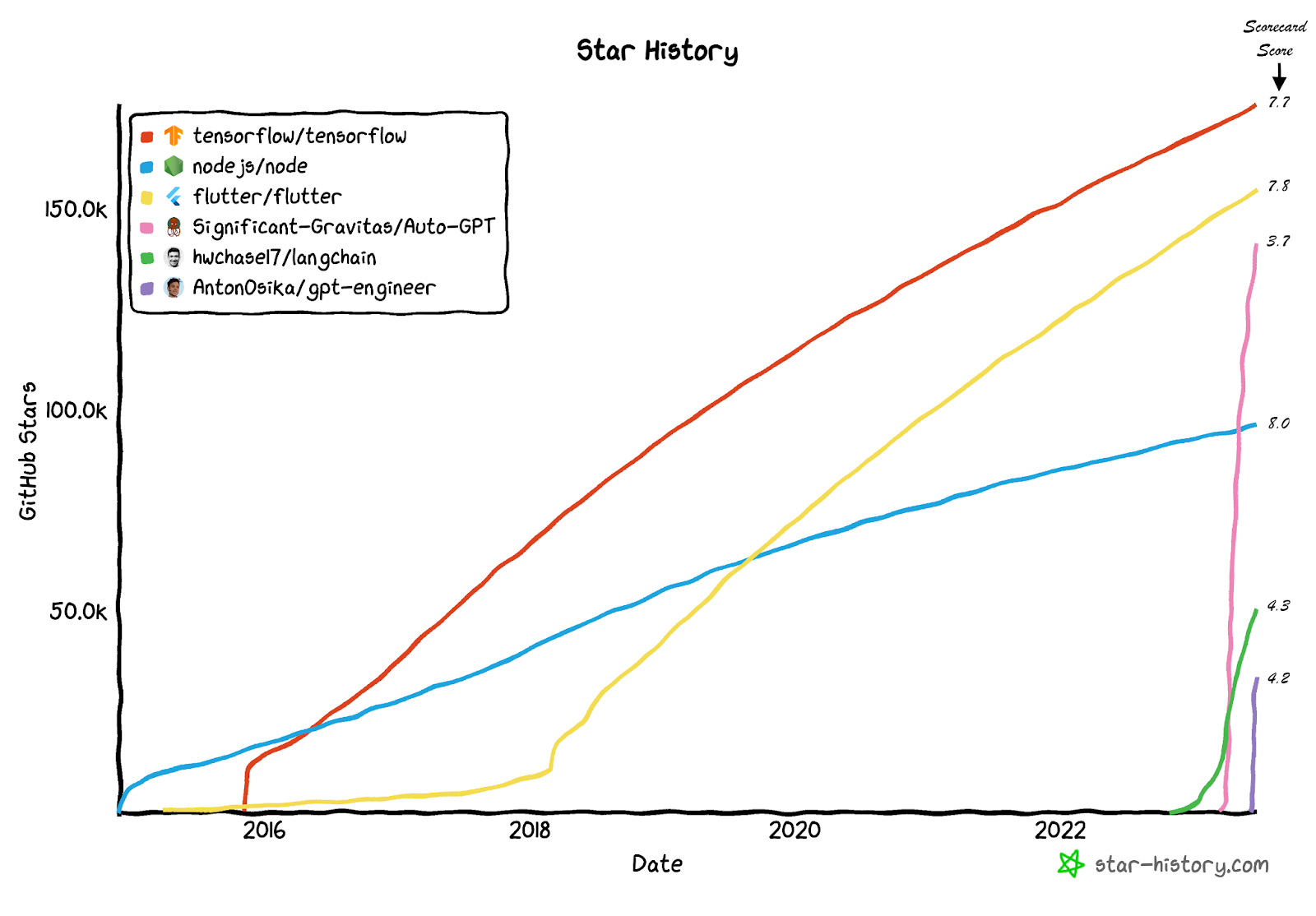
Source: star-history.com
As these systems gain popularity and adoption, they will inevitably become attractive targets for attackers, leading to the emergence of significant vulnerabilities. Our research raises concerns about the overall security of LLMs and highlights the need for improved security standards and practices in their development and maintenance.
Early adopters of Generative AI, particularly LLMs, must prioritize comprehensive risk assessments and robust security practices throughout the Software Development Life Cycle (SDLC). By carefully considering security risks, organizations can make informed decisions about adopting Generative AI solutions while upholding the highest standards of scrutiny and protection.
Looking ahead, the risk posed by LLMs to organizations will continue to evolve as these systems gain further traction. Without substantial enhancements in security standards and practices, the likelihood of targeted attacks and the emergence of vulnerabilities will rise. Organizations must recognize that integrating Generative AI tools requires addressing both unique challenges and general security concerns and adapting their security measures accordingly, ensuring the responsible and secure use of LLM technology.
Read our comprehensive research report, where we will unveil in-depth insights into the security landscape surrounding Large Language Models and provide actionable recommendations to safeguard your AI-powered future.
About the author: Yotam Perkal is the lead vulnerability researcher at Rezilion, specializing in vulnerability validation, mitigation, and remediation research. He brings extensive expertise in vulnerability management, open-source security, supply chain risks, threat intelligence and fraud detection (with 8 patents in those domains). Yotam is an active member of various OpenSSF working groups, focusing on open-source security, as well as several CISA work-streams on SBOM and VEX.



