




Rezilion Outperforms Leading Vulnerability Scanners in Benchmark Analysis




According to recent research, Rezilion’s vulnerability scanner was 12% more accurate at identifying existing vulnerabilities vs. industry standard (94% vs. 82% average precision).
Vulnerability scanners and software composition analysis (SCA) tools are an inherent part of the secure development life cycle (SDLC) process. They offer visibility into a potentially vulnerable software attack surface in the form of vulnerable packages, allowing developers and security practitioners to take action on their findings (patch or mitigate the risk) and thus minimizing the risk of using these vulnerable components.
That said, users of these tools tend to rely on them as a single source of truth when it comes to identifying vulnerable software components in their environment. Hence, when choosing a tool, the quality of their results should be a crucial consideration.
However, vulnerability scanners and SCA tools tend to produce false positive results and are also prone to false negative results.
- False positive results create unwanted noise, which eventually costs the organization time on triaging and addressing vulnerabilities that do not pose an actual risk to the environment.
- False negative results produce blind spots for the organization, which means the organization is vulnerable to certain vulnerabilities, but since the scanner isn’t able to identify these vulnerabilities, no action is taken to mitigate the risk.
Currently, no transparent data source objectively evaluates these tools or determines the quality of their results.
Recently, Rezilion conducted a benchmark analysis of several leading open source and commercial vulnerability scanners and SCA tools to both provide a performance evaluation and pinpoint some of the main reasons for these false positive and false negative results.
Methodology of Vulnerability Scanner Research
The research compared seven different vulnerability scanners and SCA tools against a benchmark of 20 of the most popular container images on DockerHub.
Performance was evaluated using the following three metrics:
- Precision, which takes into account false positive results
- Recall, which takes into account false negative results
- F1-Score, which combines precision and recall into a single metric
A more detailed explanation of the evaluation method can be found in Appendix A.
Results
The following table shows Rezilion’s scanner performance against the industry average as reflected by the benchmark analysis:
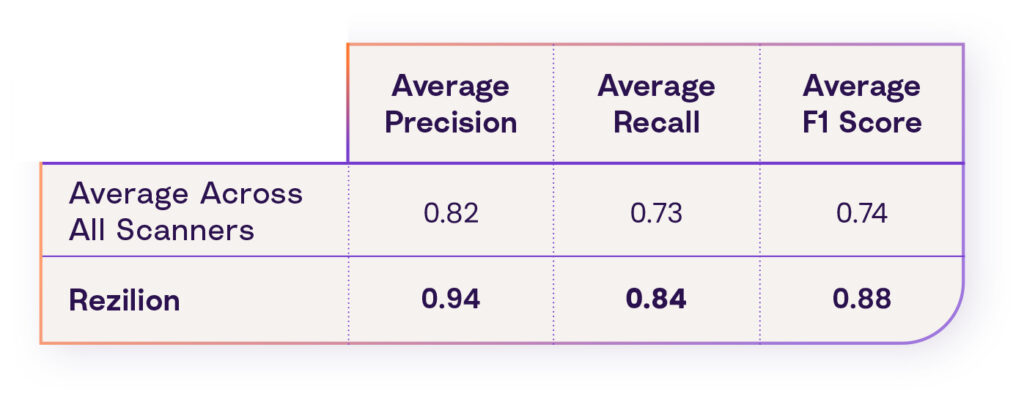
Average Precision, Recall, and F1-Score per Scanner
As can be seen from these results:
- In terms of precision, which reflects the percentage of correctly identified reported vulnerabilities (not a false positive), Rezilion outperforms the industry average by 12%.
- In terms of recall, which measures false negative results (vulnerabilities that should have been identified yet weren’t), Rezilion outperforms the industry average by 11%.
Upon analyzing the results, we identified multiple factors that affect the scanner’s performance. Examples include:
- Variance in ecosystem support – In simple terms, some scanners support certain ecosystems (such as Golang, Rust, PHP, Ruby, and Node.js ) while others do not. Even within a given ecosystem, which artifacts the scanner examines in order to detect the installed packages varies significantly between the different scanners, which could affect performance.
- Failure to account for the context in which the vulnerabilities were identified – Several of the scanners examined do not properly take into account the individual OS security advisories (such as Debian security advisory or Ubuntu security advisory).
- Reliance on Common Platform Enumeration (CPE) – CPE is a structured naming scheme for information technology systems, software, and packages. CPEs were designed for IT asset management, not to map vulnerabilities to software components. Since there is no way to control the naming of open source components (especially across different run times), CPE uniqueness cannot be enforced. In addition, the rate at which software is developed and released makes it impractical to expect a single central dictionary, such as the one maintained by NIST, to provide a complete and accurate reflection.
Hence, every scanner that solely relies on CPEs to match vulnerabilities to software components is highly susceptible to false positive results.
- Usage of software not managed by package managers – Standard vulnerability scanners and SCA tools rely on package manager metadata to determine what packages are installed on the scanned computer. In a real-world setting, package managers are not the only way to install a software component. In these cases, the scanner will not be aware of a software’s existence and consequently fail to report any vulnerabilities associated with it.
- Lack of built-in runtimes support – Certain runtimes, such as Golang, can be built into the executable binary. In this case, an installation of Golang isn’t necessary to exist on the container as the package binary is statically linked, thus it can be executed as a standalone binary. Scanners that do not account for these cases could potentially fail to report on existing vulnerabilities.
The full analysis can be found in the detailed research report here.
Conclusion: Huge Variabilities Exist in Scanners
While conducting the analysis, we noticed a huge variability in the performance results of the different tools. Moreover, no two scanners agreed on the detected vulnerabilities in the different test environments.
Thus, and in light of the above-mentioned root causes, when choosing a SCA solution, it is important to understand the capabilities and limitations of the examined tools and make sure that your scanner of choice matches your specific needs.
As a user, you should ask yourself the following questions:
- What are the runtimes my scanner of choice supports?
- Does my environment have code in runtimes that are unsupported?
- For the supported runtimes, which artifacts does my scanner rely on in order to identify existing components? For example, a scanner with Golang support that only supports go.mod files will not report on vulnerabilities in the Golang runtime itself, only on vulnerabilities in Go modules.
- What is the target environment to be scanned? Not all tools are adequate for scanning both Dev CI/CD and production environments as the artifacts they rely on might not exist in each of the target environments. For example, if I aim to scan my production environment, will my scanner of choice be able to report on vulnerabilities in compiled binaries?
- What are the security advisories my scanner relies on?
Appendix A – Evaluation Method
Each scanner was treated as a binary classifier that aims to identify whether a specific package and version combination installed on the system is vulnerable. Each potential vulnerability had two possible output classes:
1 – The vulnerability exists in the scanned environment
0 – The vulnerability does not exist in the scanned environment
In this context, we defined:
- True Positive (TP) – A scanner accurately identified a vulnerability
- True Negative (TN) – A scanner accurately claimed a vulnerability doesn’t exist
- False Positives (FP) – A scanner wrongfully claimed a vulnerability exists
- False Negative (FN) – A scanner wrongfully claimed a vulnerability doesn’t exist
A scanner’s results were evaluated using the following performance metrics:
- Precision – How many of the total positive samples (including those not identified correctly) were identified correctly? Precision was calculated as follows:

- Recall – How many actual positive samples were identified correctly? The recall was calculated as follows:

Where TP = True Positive; FP = False Positive; TN = True Negative; FN = False Negative.
F1-Score – The F1-Score, also known as the Harmonic Mean, combines precision and recall into a single metric. This measure compared the performance of the different scanners. The F1-Score was calculated as follows:




