




Is Your Vulnerability Scanner Giving You Reliable Results?




In a software-driven world, the number of newly discovered software vulnerabilities is constantly on the rise globally. Organizations rely on vulnerability scanners and Software Composition Analysis (SCA) tools to detect vulnerabilities in their software.
But new research from Rezilion finds that relying on vulnerability scanners does not guarantee reliable results. In fact, our tests found mediocre accuracy in today’s most popular commercial and open-source scanning technologies. The results also provide insights into the main causes for vulnerability misidentifications.
In previous research, our findings revealed that 85% of correctly identified vulnerabilities don’t pose an actual threat since they’re not actually exploitable in runtime. The current research focuses on the initial identification of these vulnerabilities (regardless of their exploitability) and exposes huge variability in the capability and accuracy of different scanning tools. With new bugs cropping up daily, an alarming amount of false positive and false negative results give organizations a misleading sense of their own security posture. Discrepancies in scanner results can lead to massive vulnerability backlogs full of bugs that don’t pose a real threat, and also to major blindspots to real, critical vulnerabilities that do pose a threat to the environment.
We decided to take action and proactively improve the state of vulnerability misidentifications across the entire ecosystem. This research is the first part of that initiative. In it, we will shed a light on the main reasons why scanners either falsely report on a non-existent vulnerability or miss an existing vulnerability.
Armed with this information, we believe end-users can understand the capabilities and limitations of various scanning technologies and make informed decisions when choosing the right tools for their needs.
Our Approach to the Scanner Research
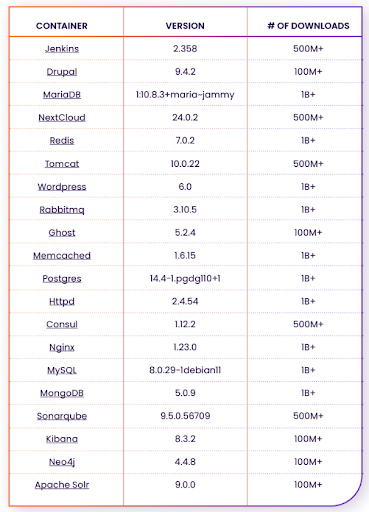
In this research, we examined 20 of the most popular containers on DockerHub,
ran them locally, and scanned them using six different vulnerability scanners. The scanner results were analyzed along with the software components on the container images. Results reveal of the 20 containers examined, each vulnerability scanner reported a different number of vulnerabilities.
These are the containers used in the current benchmark analysis:
In order to evaluate the performance of the different scanners, we decided to treat each scanner as a classifier that aims to identify whether a specific package and version combination installed on the system is vulnerable. More specifically, we can make an analogy to a binary classifier that for each potential vulnerability has two output classes:
1 – The vulnerability exists in the scanned environment
0 – The vulnerability does not exist in the scanned environment
In this context we will define:
- True Positive (TP) – A scanner accurately identified a vulnerability
- True Negative (TN) – A scanner accurately claimed a vulnerability doesn’t exist
- False Positives (FP) – A scanner wrongfully claimed a vulnerability exists
- False Negative (FN) – A scanner wrongfully claimed a vulnerability doesn’t exist
In order to evaluate the results of the different scanners we will use the following performance metrics:
- Precision – How many of the total samples reported (including those not identified correctly) were identified correctly? Precision is calculated as follows:
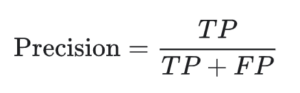
- Recall – How many actual positive samples were identified correctly? The recall is calculated as follows:
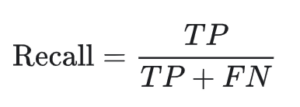
Where TP = True positive; FP = False positive; TN = True negative; FN = False negative.
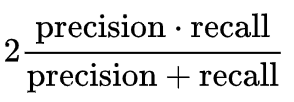
F1-Score – The F1-Score, also known as the Harmonic Mean, combines precision and recall into a single metric. This is the measure we will use in order to compare the performance of the different scanners. The F1-Score is calculated as follows:
Inconsistent Results in Scanners are Common
In the following table you can see the performance of the different scanners across the 20 examined containers:
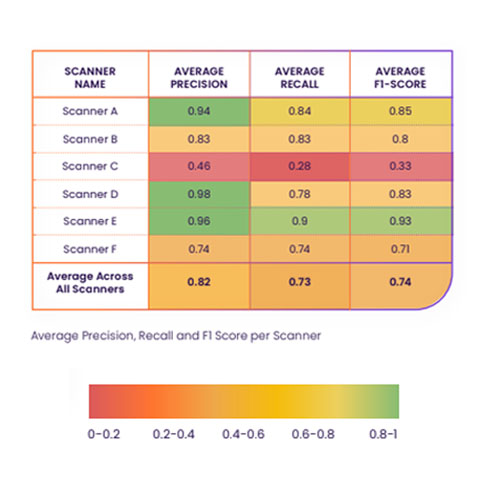
Note: Since our goal is truly to drive improvement across the board and not to “point fingers” we have decided not to name the vulnerability scanners at this stage. The scanners will be referenced as Scanner A through Scanner F.
A few key statistics from the research:
- Recall: Compared to the ground truth (i.e., taking false negatives into account), scanners returned only 73% of relevant results out of all vulnerabilities that should have been identified, including those the scanners failed to detect.
- Precision: On average, out of the total number of vulnerabilities reported by the scanners, only 82% were relevant results (identified correctly), regardless of vulnerabilities that scanners failed to report (18% were false positives).
- Over 450 high and critical-severity vulnerabilities were misidentified across the 20 containers.
- On average, across the 20 containers examined, the scanners failed to find (false negative result) more than 16 vulnerabilities per container.
In other words, when you run a single vulnerability scanner, it doesn’t matter which one, you get noise that stems from false positive results and at the same time you will have vulnerabilities in your environment that will not be identified at all (false negative results), hence you will be unaware of their existence.
We then performed root cause analysis in order to identify the causes for the false positive and false negative results and identified a variety of reasons for vulnerability misidentification including varying ecosystem support, failure to take into account the context in which the vulnerability was identified, data issues, lack of support for packages installed not via package managers and more…
As a result, Rezilion has opened issues/support tickets for the misidentification of over 1600 different CVEs. The full research report gives detailed explanations as well as concrete examples for each.
By providing transparency into these gaps, pinpointing the core reasons for them, and bringing them to the attention of the different vendors, Rezilion researchers hope to help improve the reliability/performance of these tools for the industry as a whole.
Final Thoughts: Cutting Through the Noise of Inaccurate Scanner Results
As clearly demonstrated by the research, today’s best scanners are only partially effective. Most scanners have blindspots and create noise that both security and development teams then have to deal with, which causes costly risk and delay, daily.
We are accustomed to accepting inaccuracies as an inherent part of vulnerability scanning. These inaccuracies cost time spent triaging irrelevant vulnerabilities and worst, in the case of false negative detections, create blind spots for the organization and a false sense of security.
A primary problem is that the scanner data is not transparent. End-users have no way of evaluating the performance of vulnerability scanners.
In this research, and subsequent research to be released in the coming months, we decided to take a proactive approach and try to improve the current state. We hope this research will help drive the entire industry forward and improve the quality of vulnerability scanning across the board.
In the interim, end-users are advised to:
- Understand their specific scanner’s capabilities and limitations as well as their specific coverage needs (in terms of supported runtimes) and make sure that their scanner of choice matches their specific needs.
- Be mindful of the root-causes for misidentification as presented in the research and don’t trust scanner’s results blindly.
- Utilize a Software Bill of Materials (SBOM) to validate the accuracy of their scanner output and achieve visibility into their software dependencies.
Learn More About Scanner Inconsistencies Today
To download the full report, please visit: https://www.rezilion.com/lp/scanning-the-scanners-what-vulnerability-scanners-miss-and-why/.
Learn ways to enhance the accuracy of scan results with Rezilion Vulnerability Validation by booking a demo of our platform today.



